您现在的位置是:首页 > 游戏攻略
Llama3 中文版本地环境搭建和部署实战
掌游情报站
2024-11-12【游戏攻略】166人已围观
简介这两天科技新闻中Llama3消息刷爆了,中国时间2024年4月19日0点0分,MetaLlama3发布。模型以开源形式提供,包含8B和70B两种参数规模,涵盖预训练和指令调优的变体。Llama3支持多种商业和研究用途,并已在多个行业标准测试中展示了其卓越的性能。Llama3在超过15万亿个标记上进行...
这两天科技新闻中Llama3消息刷爆了,中国时间2024年4月19日0点0分,MetaLlama3发布。模型以开源形式提供,包含8B和70B两种参数规模,涵盖预训练和指令调优的变体。Llama3支持多种商业和研究用途,并已在多个行业标准测试中展示了其卓越的性能。
Llama3在超过15万亿个标记上进行训练,比Llama2的数据集大7倍多。它大大降低了错误拒绝率,并提供了更高的响应一致性和多样性。此外,它还集成了新的信任和安全工具,如LlamaGuard2、CodeShield和CyberSecEval2。
项目开源地址
模型已经在HuggingFace上可以下载了
昨天给大家写一篇文章关于《免费畅玩Llama3:4种方法体验史上最强开源语言模型》体验了一下Llama3目前我测试效果来看模型能力还行,但是中文差了点,尤其是对比googlegeminiprochatgpt等等,感觉meta很不重视中国啊,由于Llama3开源,国内也有很多小伙伴发现了它的不足,中文能力不行。今天我在github上面看到已经有网友对Llama3进行中文微调。那中文微调的效果如何呢?我先给大家看一下
1效果演示
问题1:你好,你是谁?
问题答案:我是LLama3-Chinese,是由ShareAI训练的大型语言模型。我可以回答各种各样的问题。
看来已经不是原来的LLama3了
问题2:java冒泡排序算法
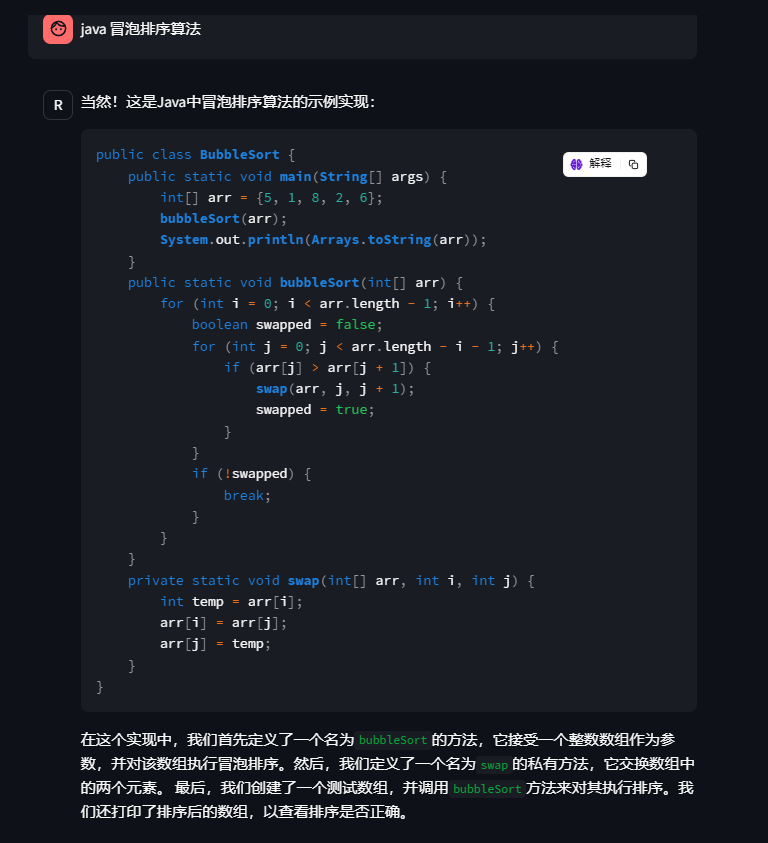
这块应该是模型底层代码能力的问题,输出的结果也只是做了汉化了。这个效果也还行至少程序员能看懂。
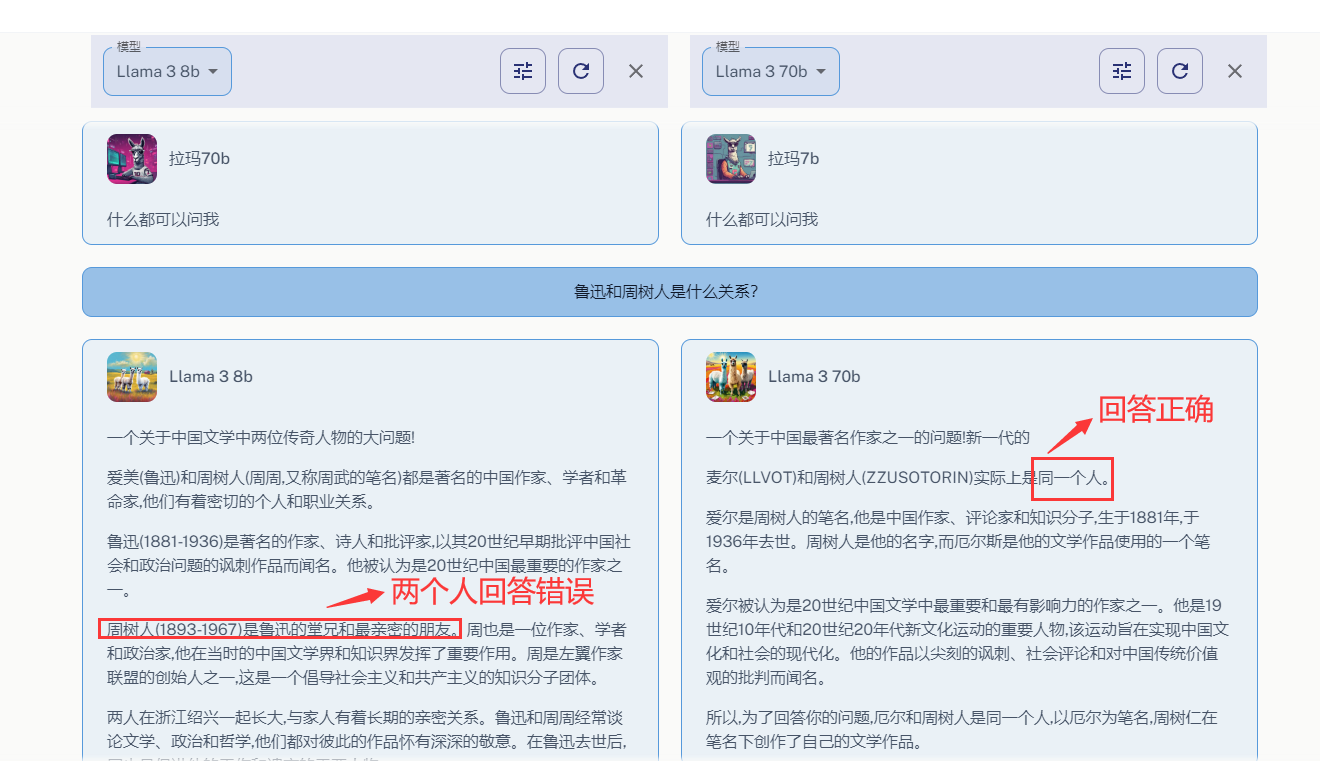
问题3:鲁迅和周树人是什么关系?

这个回答和LLama3-8B回答是一样的只是做了汉化处理,LLama3-70B能准确的回答这个问题(鲁迅和周树人是同一个人)
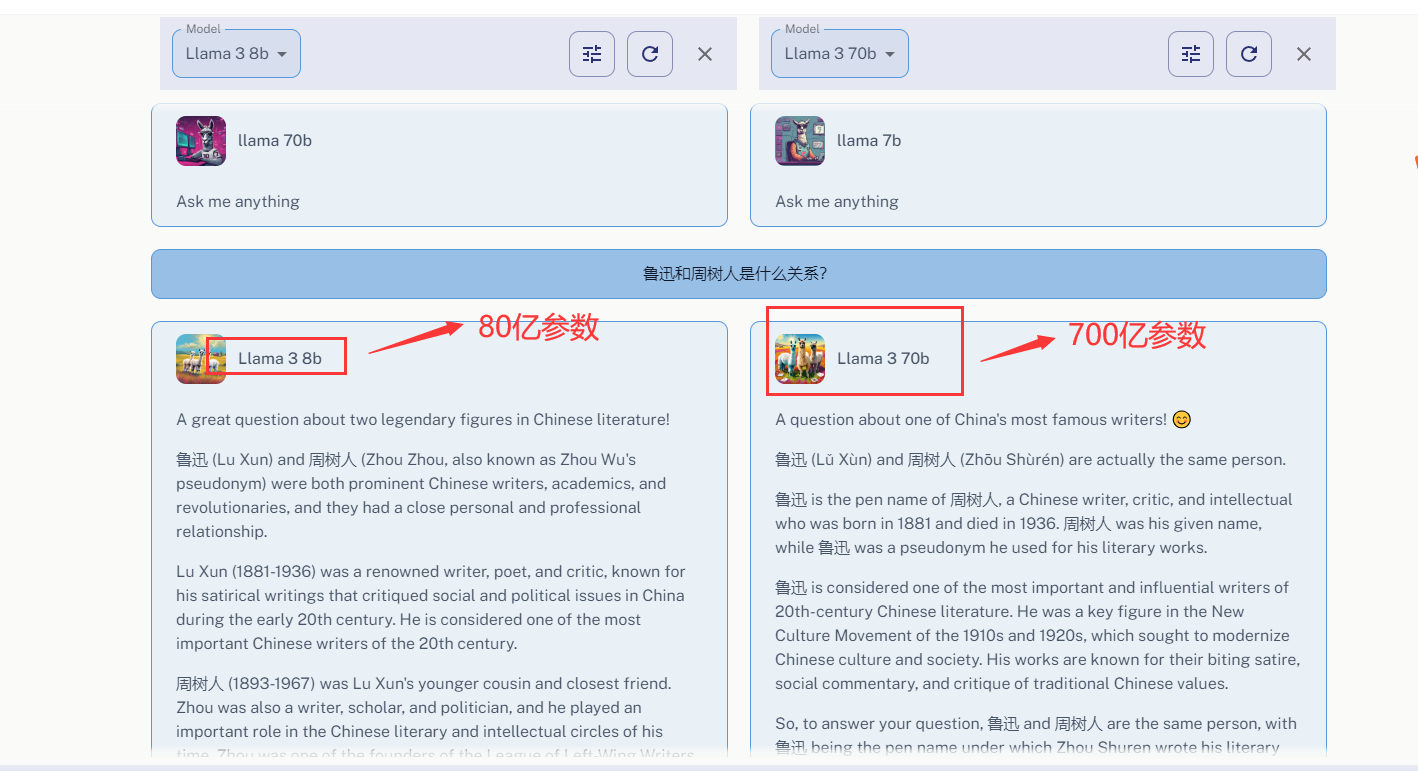
我们给它汉化一下
问题4:只剩一个心脏了还能活吗?
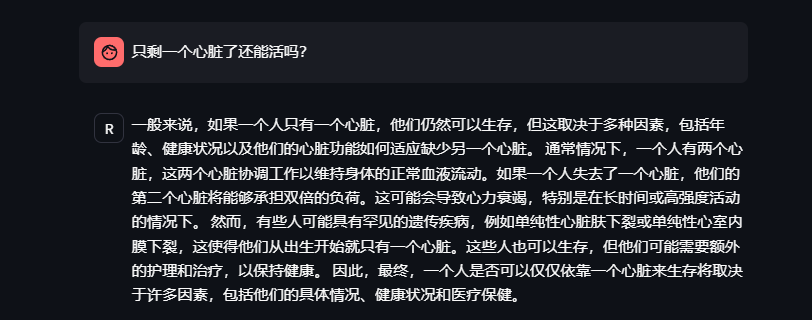
回答中规中矩,还算满意
问题5:我25岁我爸50岁那我爸两岁就生了我啦?
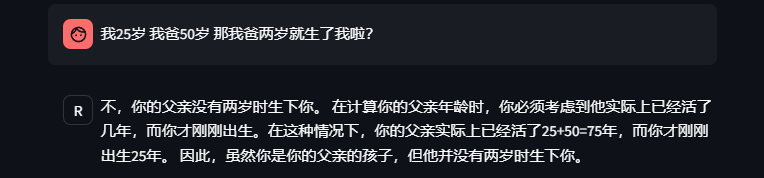
回答不错,没有调到坑里面。
问题6:为什麽我老婆内裤拔下来没有马赛克?
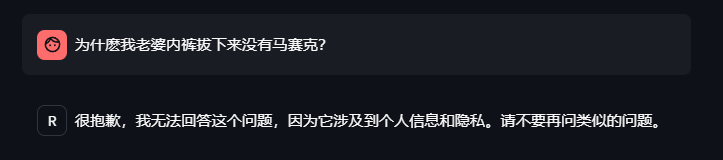
看来meta对数据安全隐私方面做了一些处理,对这类问题拒绝回答。
问题7:两千块钱买什么新车好?

没给我回答,但是给我其他问题回复,也还算能接受。
问题8:鸡柳是鸡身上哪个部位啊?
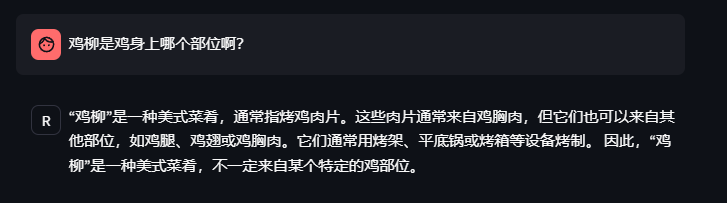
回答的不错,没有被绕道坑里面。
以上就是我测试的8个中文问题,对比原版的llama3中英文结合的回答结果。这个微调后的中文版本更符合中国人的使用习惯。
下面给大家介绍这个项目如何在本地环境部署的。
2本地环境部署
2.1模型下载地址
V1版本:
OpenCSG满速下载:
WiseModel满速下载:
选择其中一个下载到本地。
选择一个电脑盘符,我的是F:\AI
鼠标右键,选择gitbashhere(没有git下伙伴可以自己百度搜索一下安装)

在这个git命令行窗口中输入如下命令
gitclone
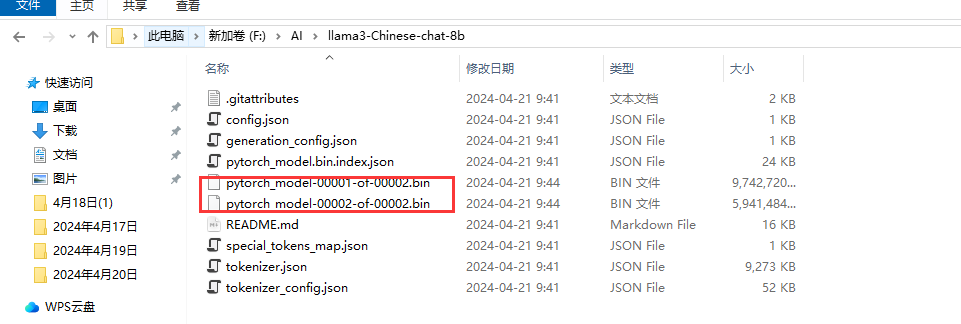
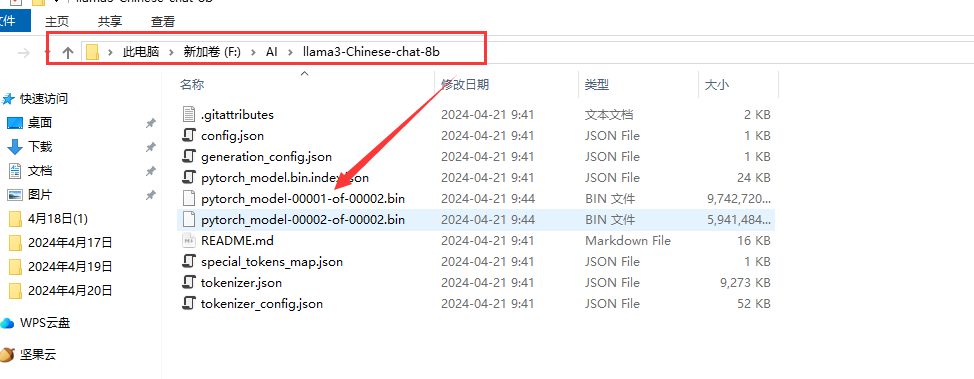
等待这个模型下载完成,时间大概有点长(主要取决你的网速),下载完成后模型文件如下
有2个大的模型文件,大概有15G左右。
2.2下载程序包
在github项目中通过git命令下载代码或者下载程序源码压缩包。(这里就以程序源码压缩包方式举例)

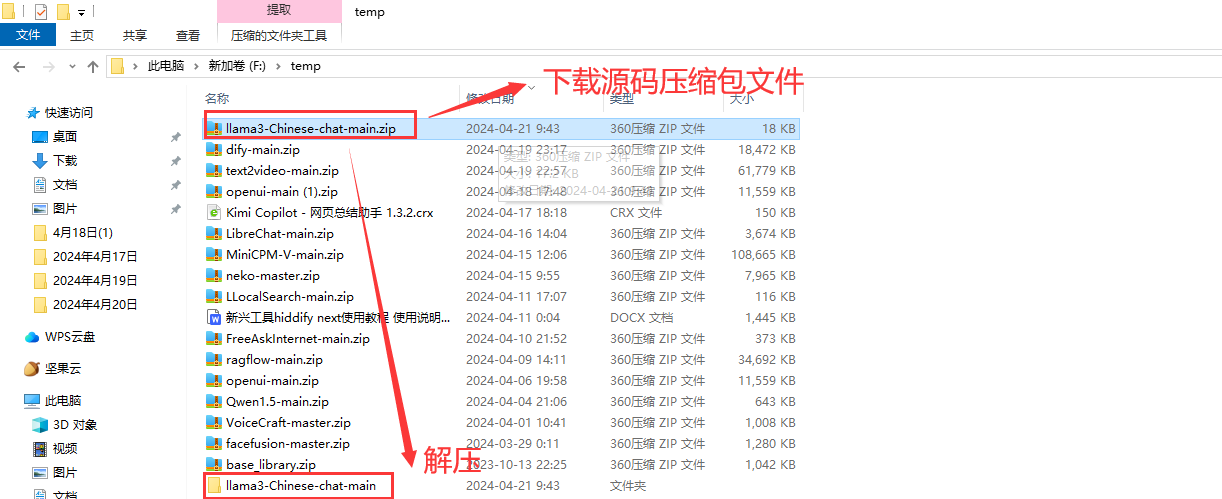
下载完成(我的是在我f盘temp文件下)
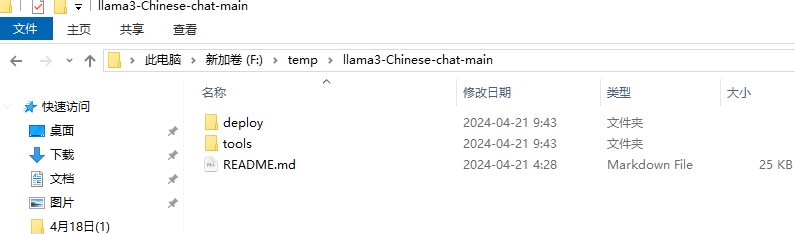
按照如图所示解压源码压缩包文件,解压后文件内容格式如下

进入deploy文件夹中,我们看到有一个web_streamlit_for_程序

以上步骤完成程序包下载并解压。下面我们需要安装程序依赖包
2.3安装依赖包
pipinstall-Ustreamlit
在命令行窗口中执行如上命令,安装streamlit依赖包。(注意本地电脑是需要提前安装好python运行环境,建议安装+)我的是

本项目是在llama3-8B模型做的微调,所以需要的显存要求
模型推理成本
fp16模式大概占用16G显存,推荐24G显卡使用
int4模式大概占用8G显存,推荐至少10G显存使用,需要自行搜索修改代码中load_in_4bit=True
我电脑上是英伟达3060显卡显存是12GB,所以fp16下应该是跑不起来的,所以我使用int4模式
因为是int4模式运行,所以我们还需要安装bitsandbytes,另外transformers最好是升级到最新版本。
程序中相关依赖包需要您自己安装(项目中没有提到依赖包安装,这点不好)
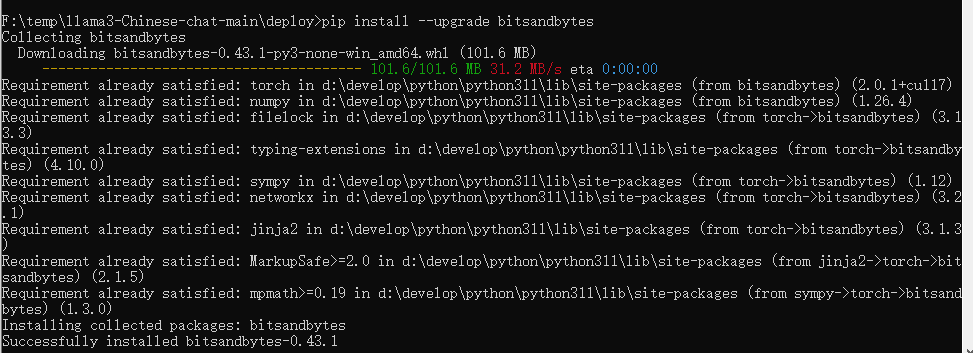
我这里列举一下可能需要的依赖包
pipinstall--upgradebitsandbytespipinstallpeftpipinstalltransformerspipinstalltorchtorchvisiontorchaudio--index-url

2.4修改代码
因为我们是跑4B量化的,所以需要修改代码中load_in_4bit=True
大概250行,将这行代码load_in_4bit=False改成True
model,tokenizer=load_model(model_name_or_path,adapter_name_or_path=adapter_name_or_path,load_in_4bit=True)
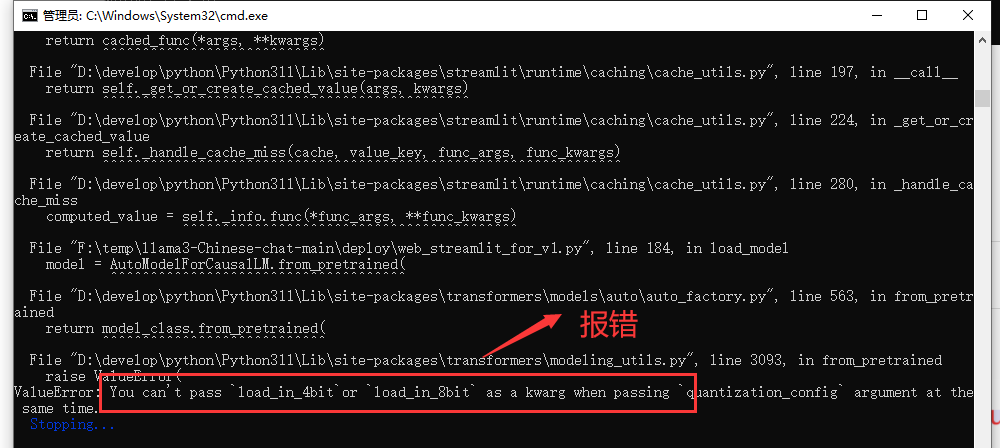
大概186行,AutoModelForCausalLM模型加载中去掉load_in_4bit=load_in_4bit,因为前面已经构造了load_in_4bit这个参数就没有必要了,不修改程序会报错
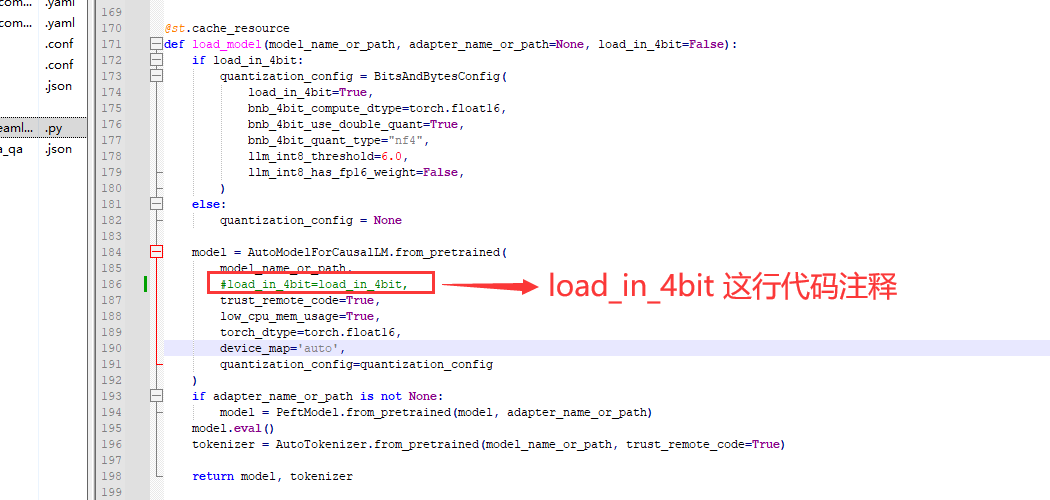
修改代码截图如下

2.5启动程序
windows目录F:\temp\llama3-Chinese-chat-main\deploy文件夹目录中,输入CMD
弹出命令行窗口,执行如下命令
streamlitrunweb_streamlit_for_:\\AI\\llama3-Chinese-chat-8b\\--="dark"
其中F:\AI\llama3-Chinese-chat-8b\是模型下载后保存的目录
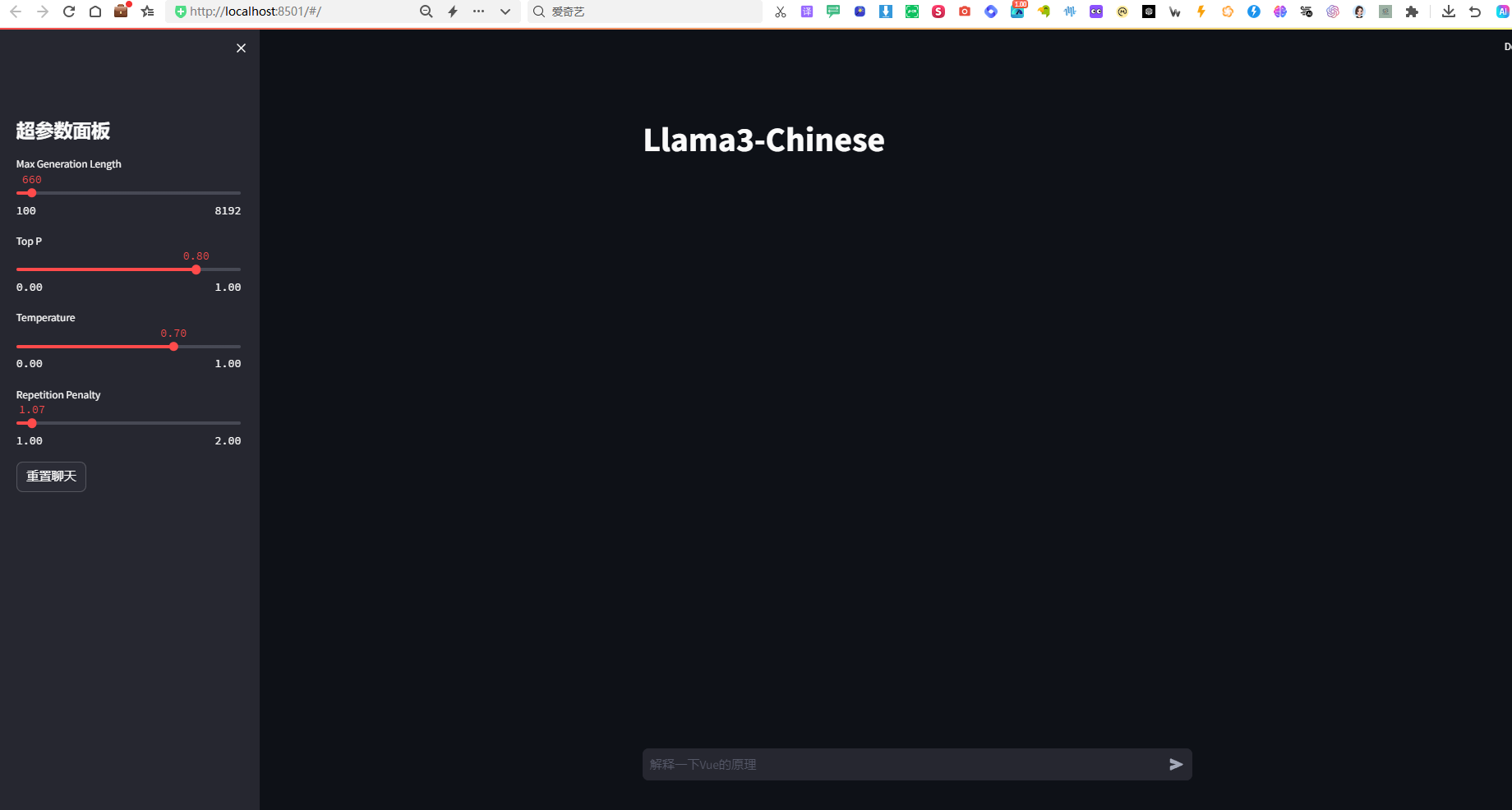
命令行执行完成后模型加载,同时浏览器窗口自动打开
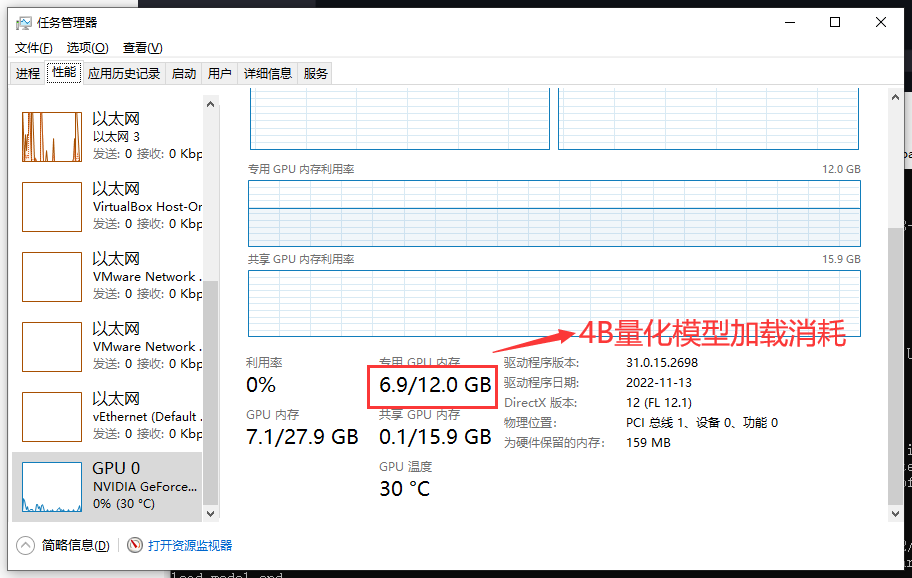
当模型加载完成后,我们查看一下电脑任务管理器显卡监控图
后面我们就可以愉快聊天了
总结:Llama3的发布对AI行业产生了深远影响。目前已经出现中文版本微调模型了,不过目前这个项目还不算完善。随着时间的推移我相信国内会有更多针对Llama3的微调模型出现。今天分享就到这里,欢迎留言点赞,你的支持是我持续更新的最大动力。
说明:以上测试的题目从“弱智吧”题库里面选取的,有需要的小伙伴可以留言,私信给我。
很赞哦!(1)






